TALK TO TWO
roboy wants a
three-way
conversation
vision
let’s talk with roboy
The goal of this project is to have a conversation with three people including Roboy. We want him to be able to tell who is saying what and store this information, so a real conversation is possible.
our goal
this semester we want roboy to …



abstract
how we did it
TRANSFORMATRIX*
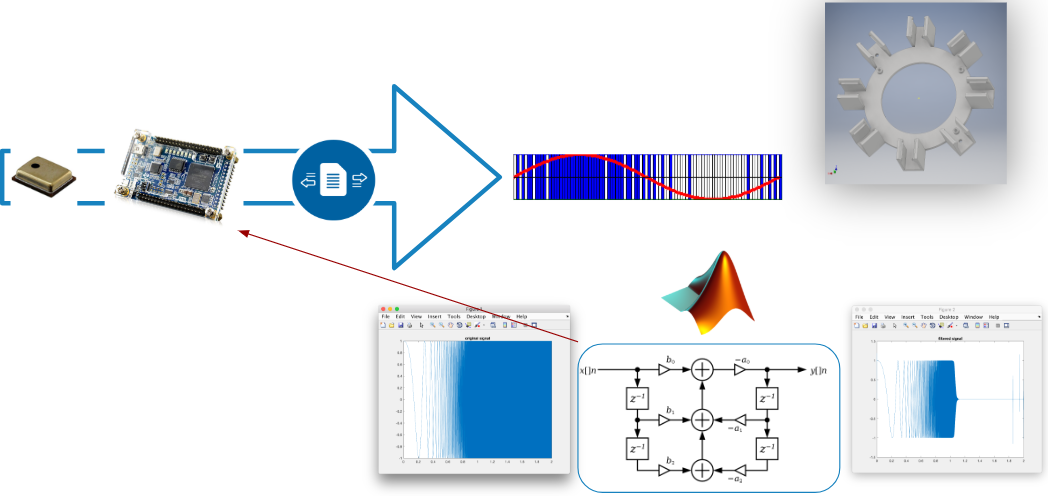
The name Transformatrix comes from our first idea of transforming the MatrixCreator, in order to use the MEMS Microphones from Infineon. By the time we realised that making our own microphone array instead is a way better approach.
What we came up with is a 3D printed model that functions as a clip-in placeholder for the modular array. The components are
- our MEMS microphone breakout board
- any FPGA (DE0 nano in the end)
Regarding software, we developed different Verilog modules. These solved the following tasks
- get the 3 MHz PDM signals from the mic
- store this signal as data and process it
- store the data in the RAM of the onboard ARM-core
Having the Data in the RAM we were able to write a script that stored the raw data in files. To get audio data out of the raw PDM data, one needs to low pass filter it. To solve this we designed a Butterworth low pass filter algorithm in Matlab that had a cut off frequency at 8kHz and downsampled the data to 16 kHz, which is a proper frequency to record human speech. The last thing that needs to be done is processing the data with this algorithm on the FPGA itself, but this is a task for da future™.
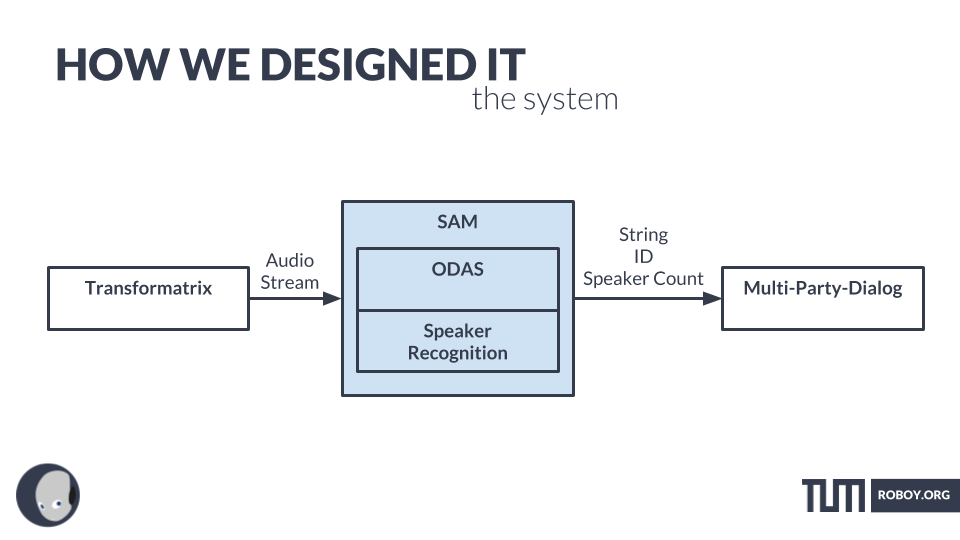
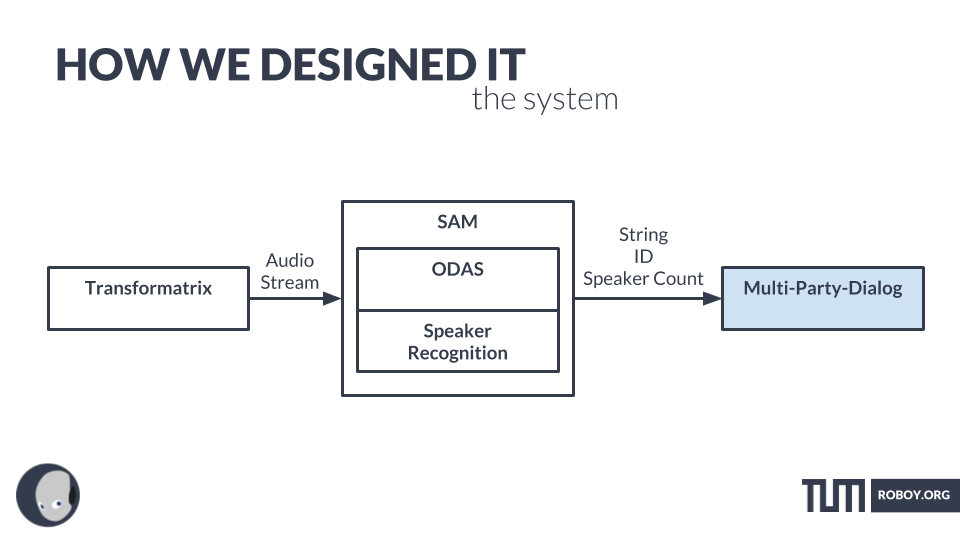
SAM – SPEAKER AND AUDIO MANAGER
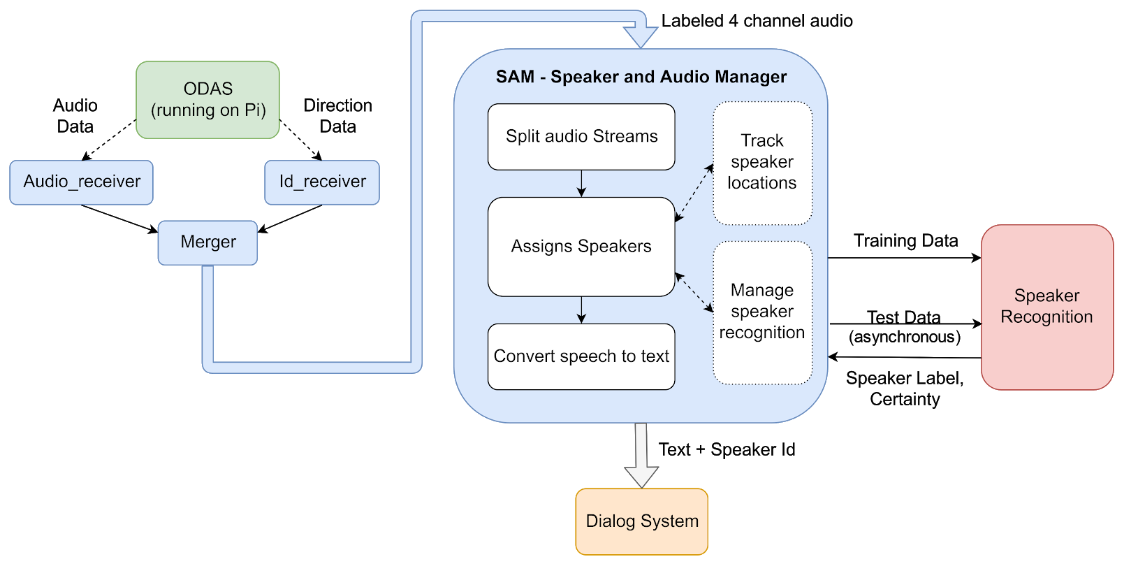
- SAM (= speaker and audio manager) is our pipeline for figuring out who said what.
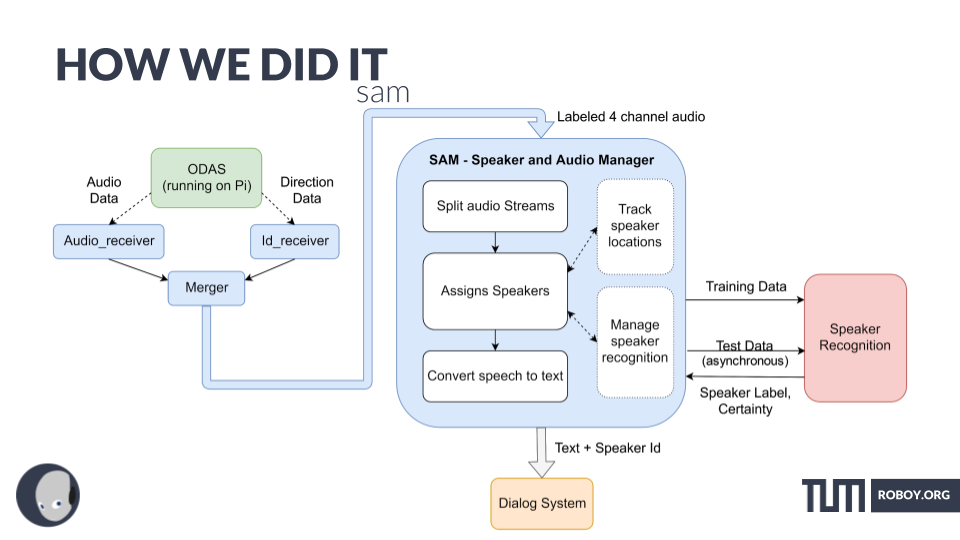
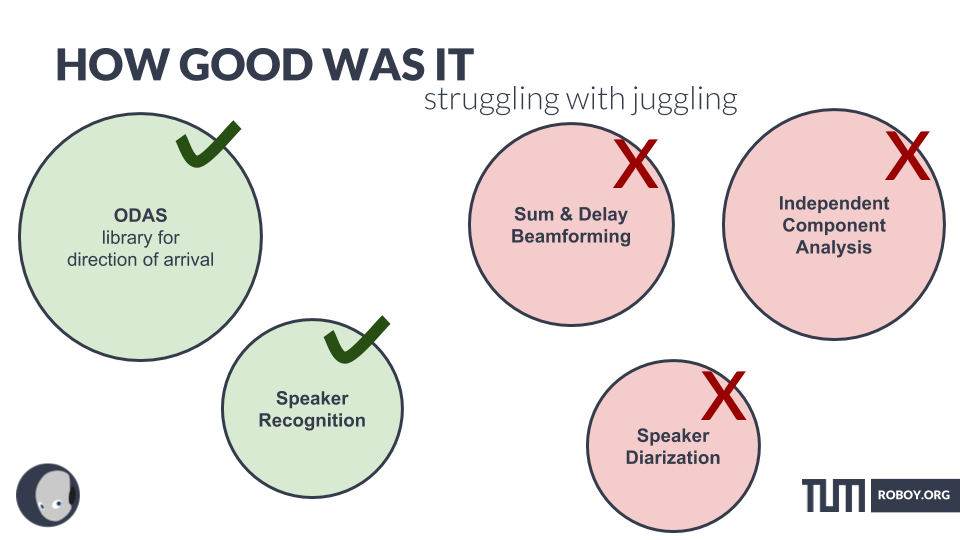
- We start with the data supplied by ODAS running on the Pi with the Matrix Creator (or our Transformatrix in the future).
- ODAS (info) stands for Open embedded Audition System. This is a library dedicated to perform sound source localization, tracking, separation and post-filtering. We use it to provide direction of arrival data, tracking the location of a sound source while its active (i.e. if a speaker is moving while he is talking) and beamformed audio (= audio filtered to contain only audio coming from that direction) for individual sources/speakers.
- We are using the sst & sss modules of ODAS:sst – sound source tracking: Providing the direction of arrival for each sound source and “tracking it”. This means that as soon as a new sound source pops up it gets assigned an id and its tracked as long as its active. Once it stops being active for a certain time (~1 sec, more on that in config) its considered dead and if a new sound comes from the same location it gets a new id.sss – sound source separation: Provides beamformed audio data for each of the sources tracked via sst.
- As the two streams of ODAS (Audio and sst data) are asynchronous they need to be merged. This is done in the Merger. It receives the data from the Audio_receiver and Id_receiver (each running in their own thread) and provides them to the main thread as python dictionaries each containing 512 samples of audio per channel and the corresponding id labels. They are stored in a Queue so that the main thread can work on them without too hard real-time constraints.
- The main thread is running an instance of SAM. We receive the audio data and split it into “recordings”. Each recording is one statement of a speaker. Once a new source (new for ODAS) pops up it is started and once the source dies for ODAS (=the speaker has finished his statement) it is stopped. An instance of this class contains the audio information from the corresponding channel, our speaker_id of the speaker and a bunch of status information indicating how far it has been processed.
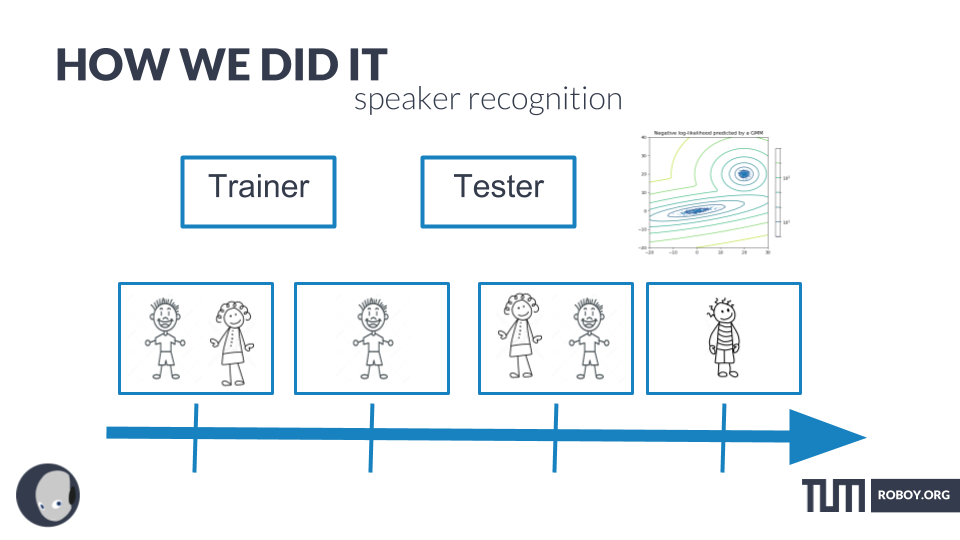
SPEAKER RECOGNITION
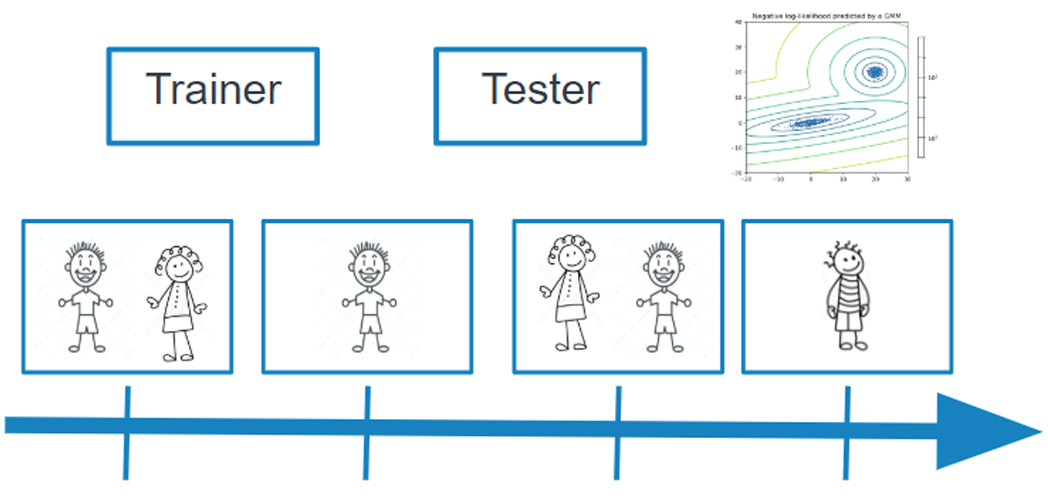
Speaker Recognition consists of two parts. First, a model is trained for each speaker based on voice features. In the second phase, this model can be used to decide which speaker of the previously seen speakers is speaking now. We also added a novelty detection so we can decide when the stream, that is tested, doesn’t belong to any of the previously trained models but must be a new person talking.
Mel Frequency Cepstral Coefficents
The voice features we use here are Mel Frequency Cepstral Coefficents (MFCC). To obtain these features the frequency bands are equally spaced on the mel scale. This approximates the human perception pretty well and therefore is used quite a lot. To get the MFCCs of an audio stream, first Fourier transform it and map the powers of the obtained spectrum to the mel scale. Afterwards you can treat the log of the mel powers as if it were a signal and discrete cosine transform it. The MFCCs are the amplitudes of this spectrum.
If you want to know more about MFCCs, check out this website.
Gaussian Mixture Models
During the training phase, we fitted Gaussian Mixture Models to the obtained features. Gaussian Mixture Models is an unsupervised learning concept that assumes that the data, it is trained on, is Gaussian distributed. During the training process, an algorithm called Expectation-Maximization tries to find the best approximation of the underlying function by fitting various Gaussian functions. Therefore Gaussian Mixture Models contain information about the centers and the covariances of the underlying function of the data points they were trained on.
The fitting of the Gaussian Mixture Models can be easily implemented in Python using scikit_learn. To obtain more information, you can go to this website.
Functionality of our code
We are using this GitHub repository (link) to extract the MFCCs of an incoming data stream. Based on these features we train a GMM for every speaker. Afterwards, during the testing, we test which of the GMMs fits best (obtains the highest score) when tested against the MFCC features of the incoming file.
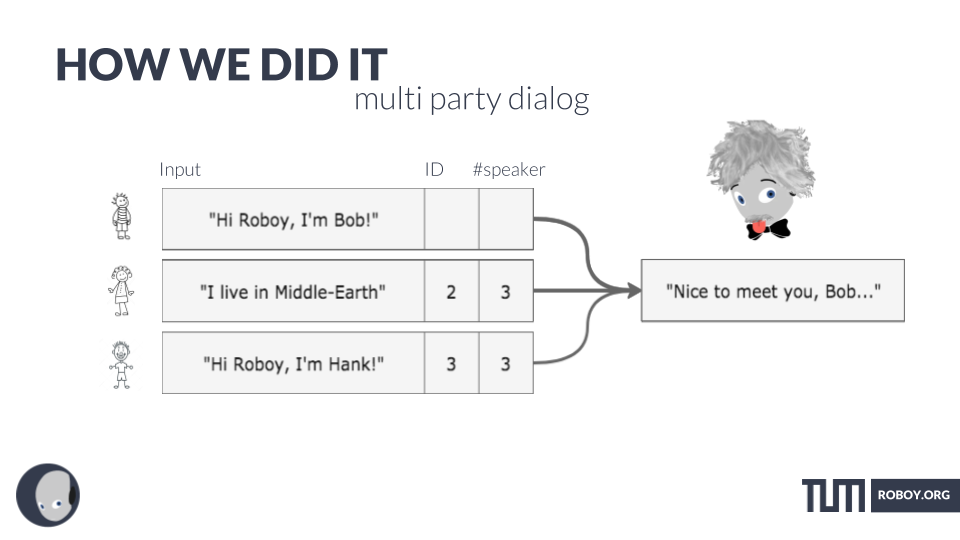
MULTI-PARTY-DIALOG
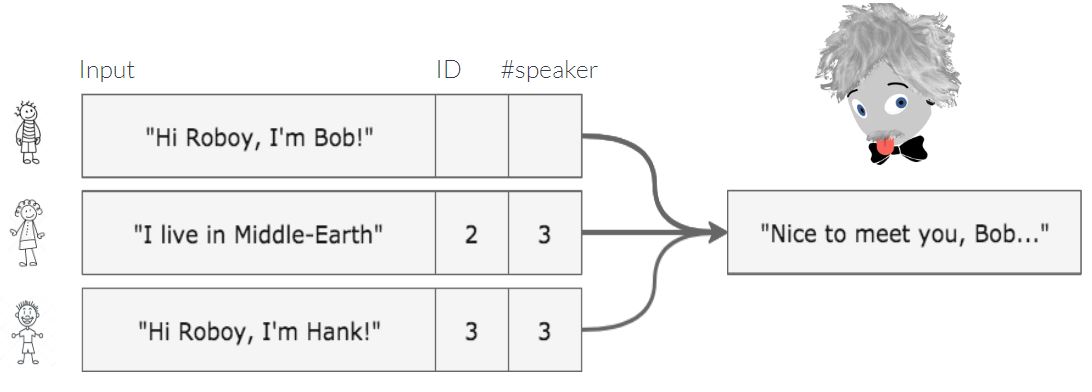
Speaker diarization is the process of splitting an audio stream into segments according to who is speaking. In order to achieve this goal, this program has the functionality of recognizing at what point of time which speaker is speaking. Before using it you have to specify how many people you want to find in the audio stream. The big downside is that it’s not working in real time. You load a .wav file after recording it and then have it analyzed. It’s possible to generate a somewhat hacky emulated realtimeness by running the algorithm every couple of seconds with the last minute or so of audio, but this is computationally quite expensive. Almost all Speaker Diarization approaches rely on audio features and therefore utilize only 1 microphone.
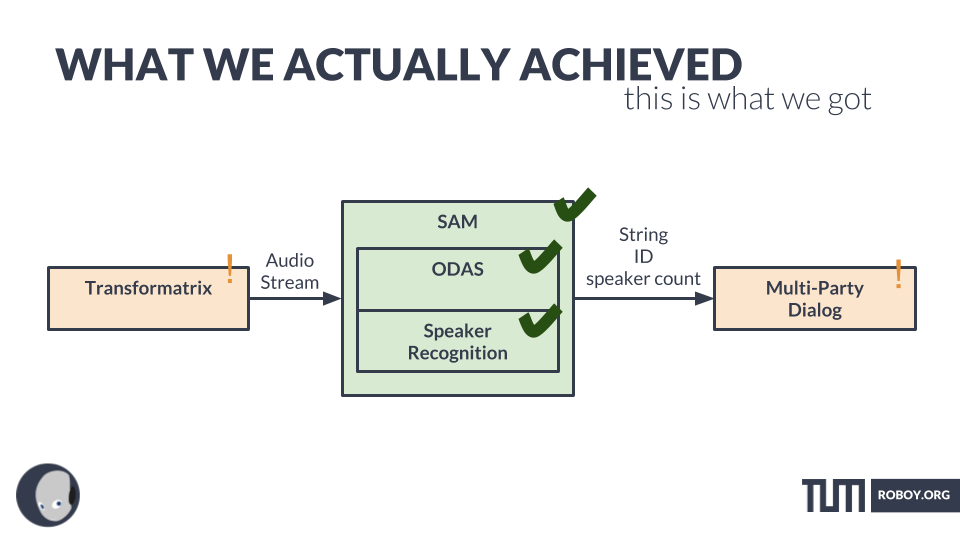
RESULTS
roboy can now…

FIGURING OUT WHO SAID WHAT
By using SAM (speaker & audio manager)
the team
get to know the talk to two team
TEAM MEMBERS SS2018
Luis Vergara (Team Lead)
Nikita Basargin (Team Lead)
Abhimanyu Sharma (Agile Coach)
Jonas Hepp
Katharina Hagmann
Kevin Just
Negin Karimi

LINKS
cad files, documentations & presentations







WANT TO JOIN A TEAM?
get in touch with us


